| Exercise 7 | Managing Writer Feature Types |
| Data | City Parks (MapInfo TAB) Walking Trail (CSV) Water Fountains (File Geodatabase) Car Parking (OpenStreetMap) Roads (OpenStreetMap) |
| Overall Goal | Create a set of data for mapping a recreational event |
| Demonstrates | Adding Writer Feature Types |
| Start Workspace | C:\FMEData2016\Workspaces\DesktopBasic\Components-Ex7-Begin.fmw |
| End Workspace | C:\FMEData2016\Workspaces\DesktopBasic\Components-Ex7-Complete.fmw C:\FMEData2016\Workspaces\DesktopBasic\Components-Ex7-Complete-Advanced.fmw |
Let's finish up your work on the fundraising walk project.
In this part of the project we’ll finalize the output requirements.
1) Start Workbench
Start Workbench (if necessary) and open the workspace from Exercise 6. Alternatively you can open C:\FMEData2016\Workspaces\DesktopBasic\Components-Ex7-Begin.fmw
2) Add Writer
If you recall, one late change was to write to PDF instead of KML. So add an Adobe PDF Writer with the following parameters:
| Writer Format | Adobe Geospatial PDF |
| Writer Dataset | C:\FMEData2016\Output\Training\CharityWalk.pdf |
| Add Feature Type(s) | Layer Definition: Copy from Reader |
Click OK. When prompted select all of the Reader feature types to copy onto the Writer:
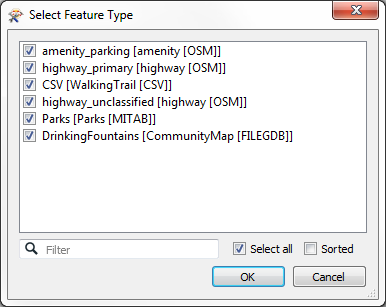
This will give a series of Writer feature types like so:
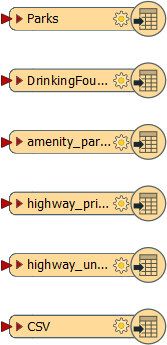
Now all that is to do is do some schema mapping.
3) Add FeatureTypeFilter
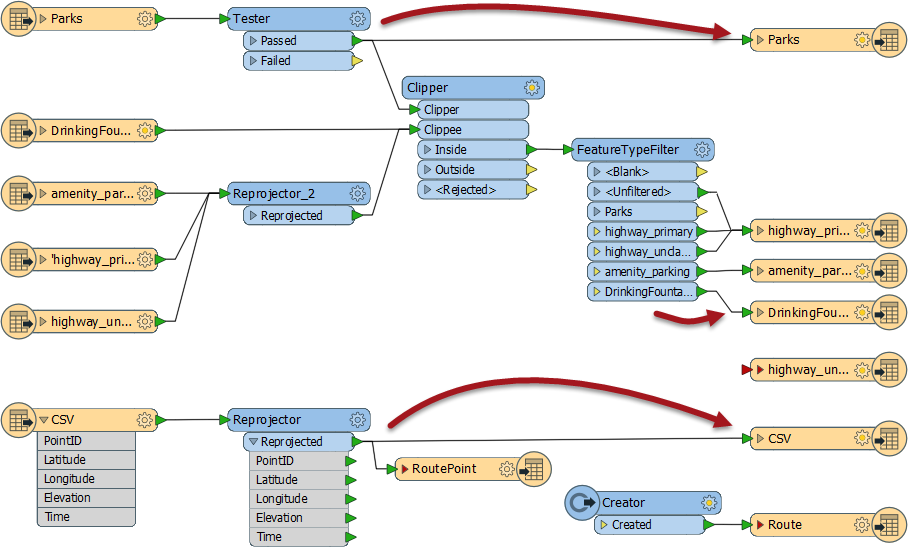
One issue about our schema mapping is that we merged a lot of data together through a Clipper transformer and it's necessary to divide it back up again if we want to write the data onto the separate layers.
So, add a FeatureTypeFilter transformer and connect it to the Clipper:Inside output port:
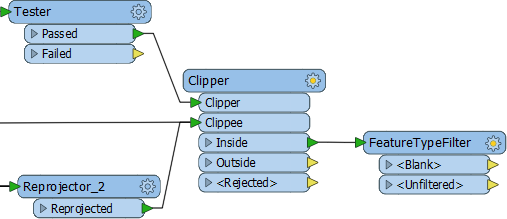
Now open the parameters dialog and click the Update button:
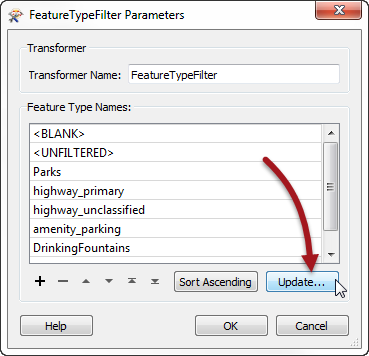
Now we can map all of our source data to the correct feature type.
4) Map Schema
OK. Make the following connections:
- Tester:Passed to PDF:Parks
- (CSV)Reprojector:Reprojected to PDF:CSV
- FeatureTypeFilter:DrinkingFountains to PDF:DrinkingFountains
- FeatureTypeFilter:amenity_parking to PDF:amenity_parking
- FeatureTypeFilter:highway_primary to PDF:highway_primary
- FeatureTypeFilter:highway_unclassified to PDF:highway_primary
- FeatureTypeFilter:Unfiltered to PDF:highway_primary
You'll note that all highway data is being sent to a single Writer feature type. Unfiltered data are the link features that entered through our merge filter.
5) Tidy Output
The only thing left to do now is tidy up some of the Writer feature types.
Firstly delete all Writer feature types that aren't being used (Track, TrackPoint, Metadata, WayPoint, highway_unclassified).
Secondly rename all Writer feature types to something more user friendly, for example:
- Rename highway_primary to Roads
- Rename amenity_parking to Car Parking
- Rename CSV to Trail Route
- Rename DrinkingFountains to Drinking Fountains
Re-run the workspace and examine the output in Adobe PDF Reader. It should look like this:
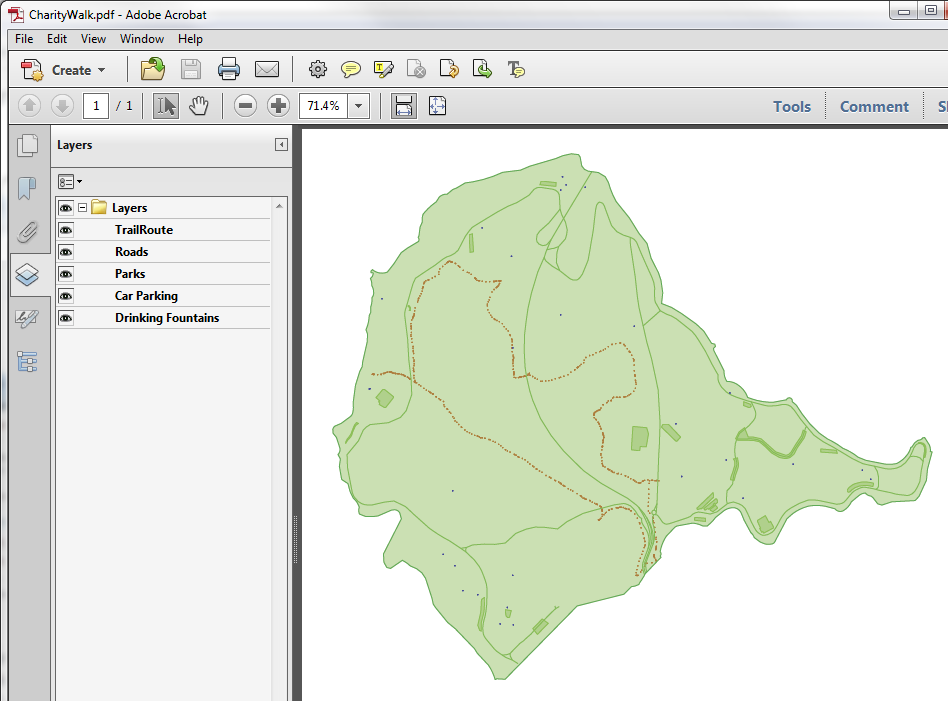
That is the end of this project. The data can now be passed on to produce the actual event map.
| Advanced Exercise |
|
Oh! Now that we dropped the KML output dataset, the Python script we wrote probably won't work!
If you have time, and have experience of Python, why not edit the script to support copying the GPX and PDF output datasets to the "shared" folder. If you have spare time, but no Python experience, why not try improving the look of the PDF output instead? Transformers you might find useful are the PDFStyler and the PDFPageFormatter. |
| CONGRATULATIONS |
By completing this exercise you have learned how to:
|