Most Valuable Transformers
If you have a thorough understanding of the most common transformers then you have a good chance of being a very efficient user of FME Workbench.
Anyone can be proficient in FME using only a handful of transformers; if they are the right ones!
The Top 25
At Safe Software, we find it useful to keep a list of the most-used transformers. It tells us where to direct our development efforts in making improvements. And no doubt it will give users a head-start on knowing which of the (400+) FME transformers they’re most likely to need in their work.
The following table provides the list of the most commonly used 25 transformers, calculated from user feedback. The Tester transformer is consistently number one in the list every year, highlighting its importance.
| Rank | Transformer | Rank | Transformer |
|---|---|---|---|
| 1 | Tester | 2 | AttributeCreator |
| 3 | Inspector | 4 | FeatureMerger |
| 5 | AttributeRenamer | 6 | AttributeKeeper |
| 7 | Creator | 8 | AttributeRemover |
| 9 | AttributeFilter | 10 | Reprojector |
| 11 | TestFilter | 12 | Clipper |
| 13 | Counter | 14 | Aggregator |
| 15 | GeometryFilter | 16 | DuplicateRemover |
| 17 | Bufferer | 18 | AttributeExposer |
| 19 | StringReplacer | 20 | ExpressionEvaluator |
| 21 | Joiner | 22 | StringConcatenator |
| 23 | VertexCreator | 24 | Sorter |
| 25 | StatisticsCalculator |
Besides the obvious transformers for transforming geometry (Clipper, Bufferer - Dissolver is #26) and the obvious transformers for transforming attribute values (StringReplacer, StringConcatenator, Counter) there are some other distinct groups of transformers.
Managing Attributes
These transformers - mostly named the Attribute<Something> - are primarily for managing attributes (creating, renaming, and deleting) for schema mapping purposes. However they can also be used to set new attribute values or update existing ones.
| NEW |
FME2016 introduces a new transformer: the AttributeManager.
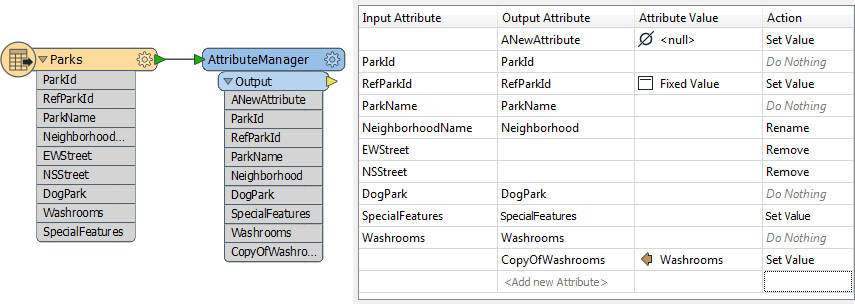
The AttributeManager is a multi-purpose transformer for carrying out most attribute-related functionality. So look out for it to appear at the top of this list - replacing all other attribute transformers - in the next year or two. |
Filtering
These transformers - mostly named the <Something>Filter - subdivide data as it flows through a workspace. Commonly the filter is a conditional filter, where the decision about which features are output to which connection is decided by some form of test or condition.
Data Joins
Joins are the opposite action to filtering; they are when separate streams of data are combined as they flow through a workspace. Like filtering there is a condition to be met - in this case matching key values - that determine how and where the join takes place.